In the previous posts, we introduced the Connascence model as a model of coupling and elaborated the different types of connascence. In this post, we will discuss how to use this model to manage coupling in software and share a number of heuristics.
Connascence is a model for reasoning about coupling and defines three dimensions of coupling: strength, degree, and distance, as the picture below shows.
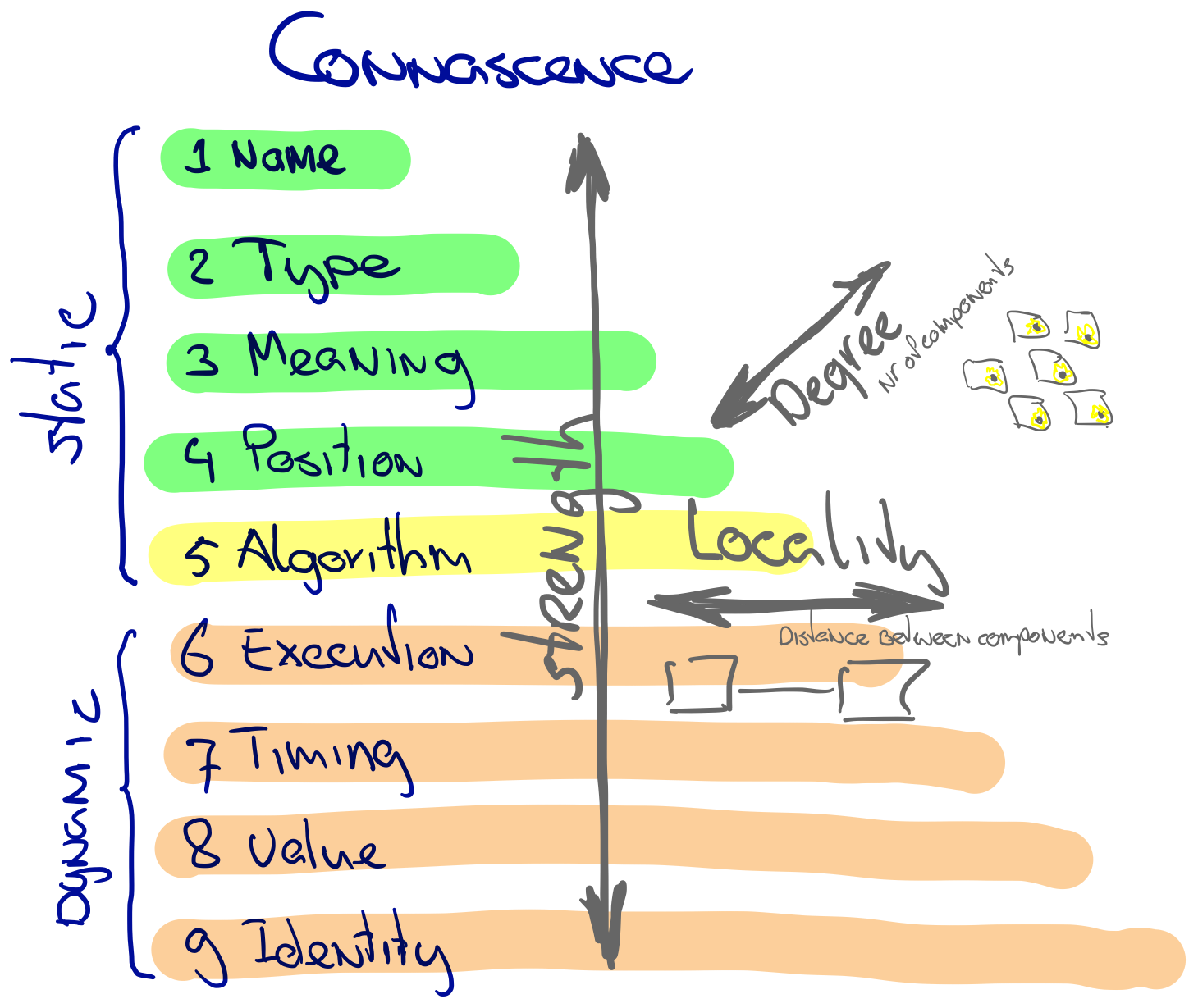
Managing coupling and cohesion with connascence
In his presentation about “The Grand Unified Theory of Software Design”, the late Jim Weirich shared a number of rules of thumb to guide refactoring towards less coupling:
- Rule of Strength
- Rule of Locality
- Rule of Degree
- Rule of Stability
Rule of Strength: try to create the weakest possible connascence.
Convert strong forms of connascence to weak forms wherever possible. Try to refactor towards static rather than dynamic connascence. Connascence by Identity or Value, for example, can be encapsulated as much as possible in a module, so that the rest of the code base has Connascence by Type.
Rule of Locality: as the distance between software elements increases, use weaker forms of connascence. If things are close together, stronger connascence is ok.
So if you cannot reduce strong connascence to a weaker form, try bringing the elements as close together as possible.
Rule of Degree: elements that have a high degree of connascence are more difficult to understand and to change.
Can this be reduced by introducing a level of indirection or an abstraction? What part is essential, what part is accidental? For example, misuse of the Singleton design pattern introduces a high degree of identity-based coupling that is not essential.
Rule of Stability: if two elements have a strong form of connascence with low locality and high degree, then they should not change. In other words, those elements should be stable. Coupling is about things that need to change together. If things don’t change, we won’t be affected by it.
In an earlier post, we mentioned the C sprintf function having Connascence by
Position with its callers. The function is widely used, so the degree of connascence is very high. The function is also
stable, so the actual risk is very low.
Managing connascence with automated tests
We can try to reduce stronger forms of connascence as much as possible and remove most of the dynamic connascence, but sometimes we are left with some connascence across codebases and services that will bite us sooner or later.
Automated testing can help. If we have Connascence by Value across the system landscape, we could capture this in an end-to-end test or in local, fast-running tests that document the value and fail whenever we change the value.
An automated test introduces a bit of extra connascence, from the test to the coupled elements, to provide early warning about one element changing without the others being updated. Especially for more dynamic forms of connascence, the test introduces a piece of explicit knowledge about what elements are coupled and why.
Static forms of connascence (name, type, meaning, position, algorithm) can often be detected using a compiler or static analysis tooling.
Detecting connascence
Dynamic connascence is harder to detect, but version control systems can provide insights. We can analyse the git history of the code to see what parts often change together, a strong hint these might be coupled somehow.
Analysing git history can also provide insights in what parts of our code are changing a lot and what parts are stable, to know where to focus on.
Examples
If we put a queue or message bus between two services, have we decoupled them?
Yes, but only to some extent. We have reduced Connascence by Timing, but we still have Connascence by Algorithm (producer and consumer need to agree on the format of the data) and Meaning (producer and consumer need to agree on how to interpret the data).
Can we avoid coupling by duplicating some code instead of introducing a shared abstraction?
It depends. If the two pieces of code look similar, but they are actually different things, they do not need to change together. A shared abstraction will introduce accidental coupling, which can make things worse.
The basic test that we should apply comes from the definition of connascence: if one changes, do we need to change the other as well to guarantee correctness? If so, the two pieces of code are connascent. Even if we duplicate, the pieces of code are still coupled, but in a more implicit way. We still have Connascence by Meaning, but spread across the code base. Instead of avoiding coupling, we risk introducing even stronger coupling!
Summary
We want ‘loose coupling’ in our software systems. But without coupling, there is no working software. Managing coupling is a key element of our work.
Connascence offers a language to talk about coupling and cohesion. It is not bound to a specific paradigm, being applicable to object-oriented programming, functional programming, SQL, stored procedures.
Coupling is not binary! The connascence model offers three dimensions to reason about coupling: strength, locality, and degree. We want to isolate strong coupling as much as possible in one place and use weaker forms of coupling when the distance and/or degree are high.
The connascence model is not perfect. The distinction between the types is not always clear, for example, between Connascence by Meaning and Connascence by Value. In practice, the ranking of the different strengths is not always that strict.
We find this model still quite useful, because:
- it provides rich vocabulary to reason about forms, degrees, and locality of coupling;
- it recognises that our goal is not getting rid of coupling, but rather keeping coupling explicit, limited, and manageable.
Further reading
- I Still Feel the Urge to Reuse Code (Even Though I Know It’s Wrong) by Martin Dilger
-
Another good read from this year is Cohesion, Modules, and Hierarchies by Eberhard Wolff
- Meilir Page-Jones, Fundamentals of OO Design in UML (1999)
- Meilir Page-Jones, Comparing Techniques by Means of Encapsulation and Connascence, in Communications of the ACM Sept 1992
- Jim Weirich, The Grand Unified Theory of Software Design, at the Acts as Conference 2009
- Connascence.io
- Vlad Khononov, Balancing Coupling in Software Design (2024)
This post is part of a series on connascence and coupling.
- Part 1 - Introduction
- Part 2 - Connascence by Name and Type
- Part 3 - Connascence by Meaning
- Part 4 - Connascence by Position
- Part 5 - Connascence by Algorithm
- Part 6 - Connascence by Execution Order
- Part 7 - Connascence by Timing
- Part 8 - Connascence by Value
- Part 9 - Connascence by Identity
- Part 10 - Heuristics for managing coupling
Credits: Scales photo by Piret Ilver on Unsplash