In the previous posts, we introduced the Connascence model as a model of coupling and elaborated connascence by name, type, meaning, position, algorithm, and execution order. In this post, we will discuss Connascence by Timing.
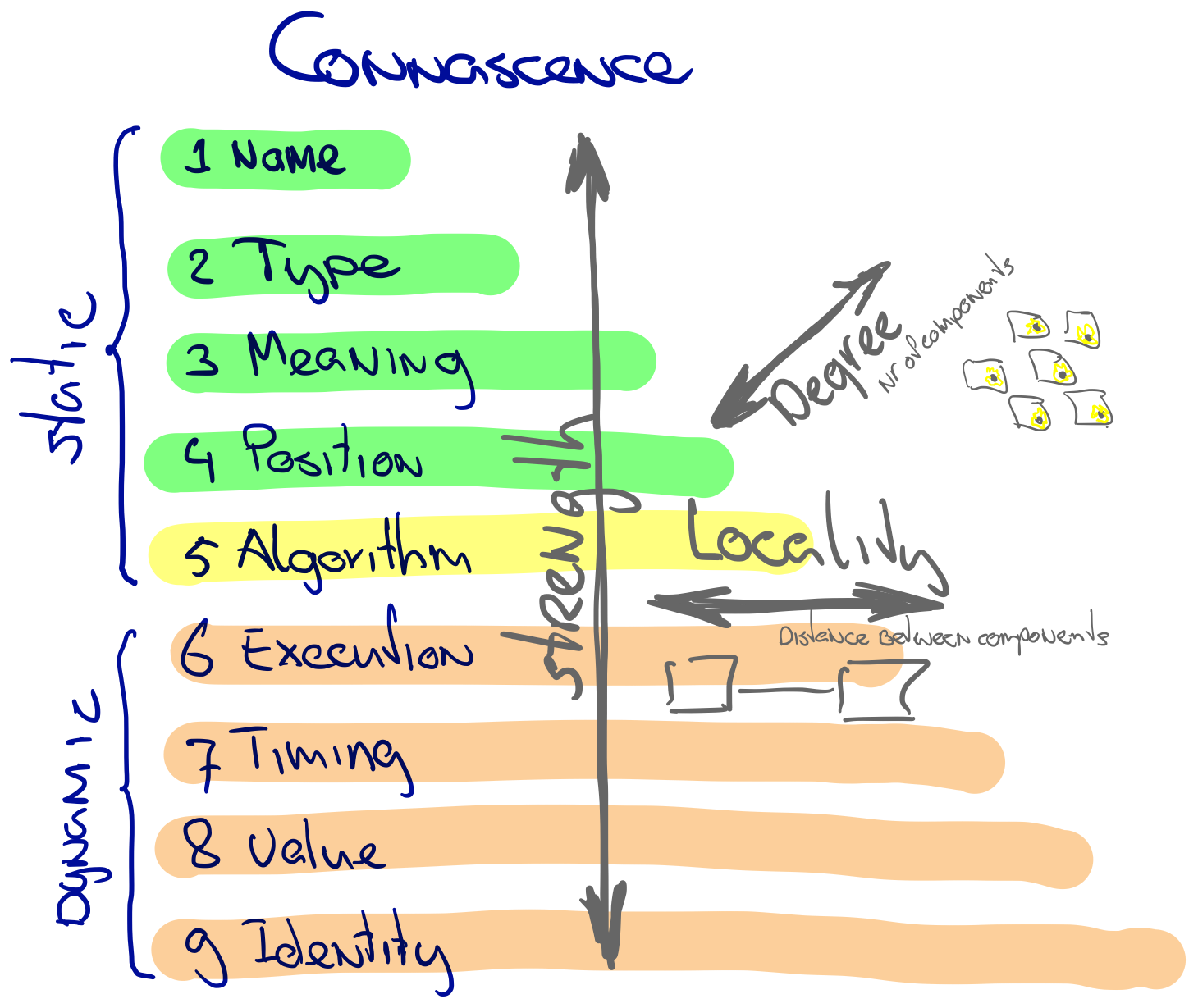
Connascence is a model for reasoning about coupling and defines three dimensions of coupling: strength, degree and distance, as the picture below shows.
Connascence by Timing
Connascence by Timing means that two elements are coupled because they need to agree on timing.

An example of Connascence by Timing is a producer and consumer exchanging data, while working concurrently and asynchronously, e.g. in separate threads or services. How do we ensure each produced value is consumed once and only once? If we don’t take any measures, we will end up with the consumer missing values and/or reading double values.

Different patterns and mechanisms are available to handle a timing dependency like this, by adding some form of synchronization. Examples are probes, semaphores, locks, futures, promises, and observables.
In some cases we can relax the consistency constraints somewhat. If we relax the exact once constraint to at least once, we reduce timing coupling. This makes synchronisation less complicated, in particular for failure scenarios. It puts a higher burden on the consumer, which should allow for duplicate values. Message idempotency helps.
What if there is a single producer and multiple consumer workers, and we need to make sure each value is read exactly once by exactly one consumer?
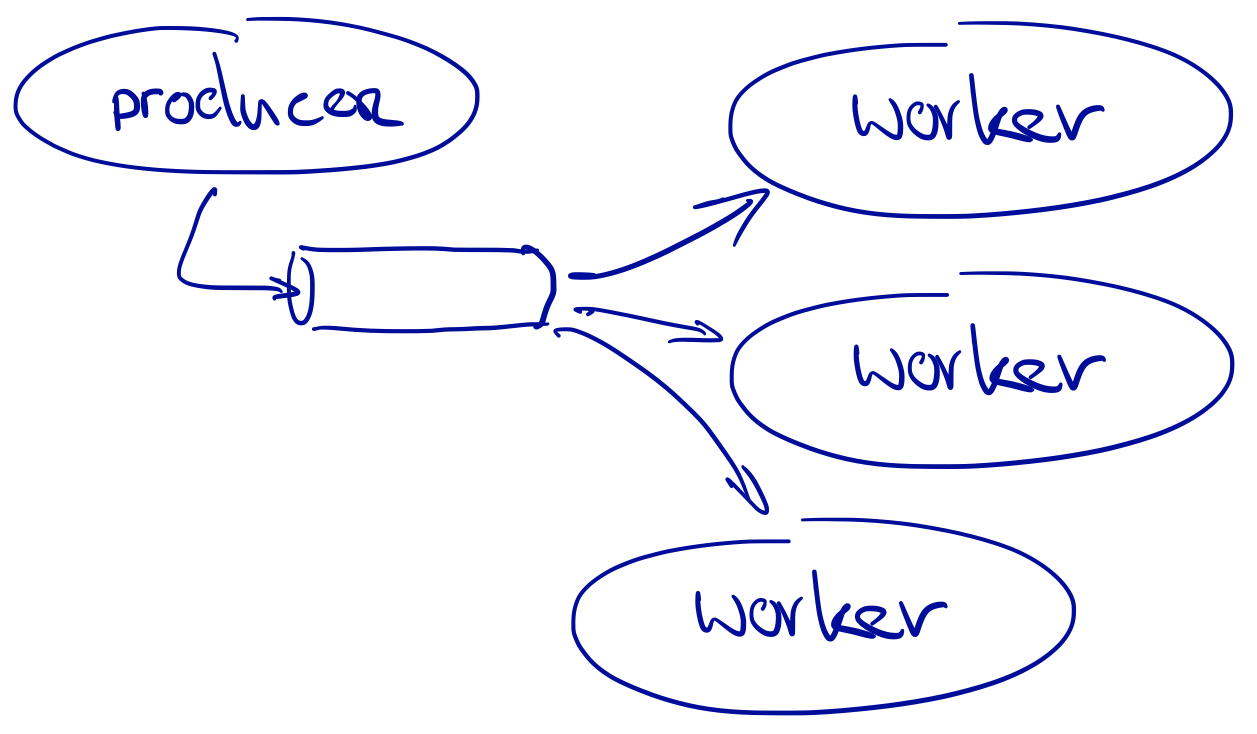
When a consumer starts reading a value, it can create a lock to ensure it is the only one reading at that moment, and release the lock when done. This trades off throughput for consistency, as the consumers sometimes need to wait while a value is processed.
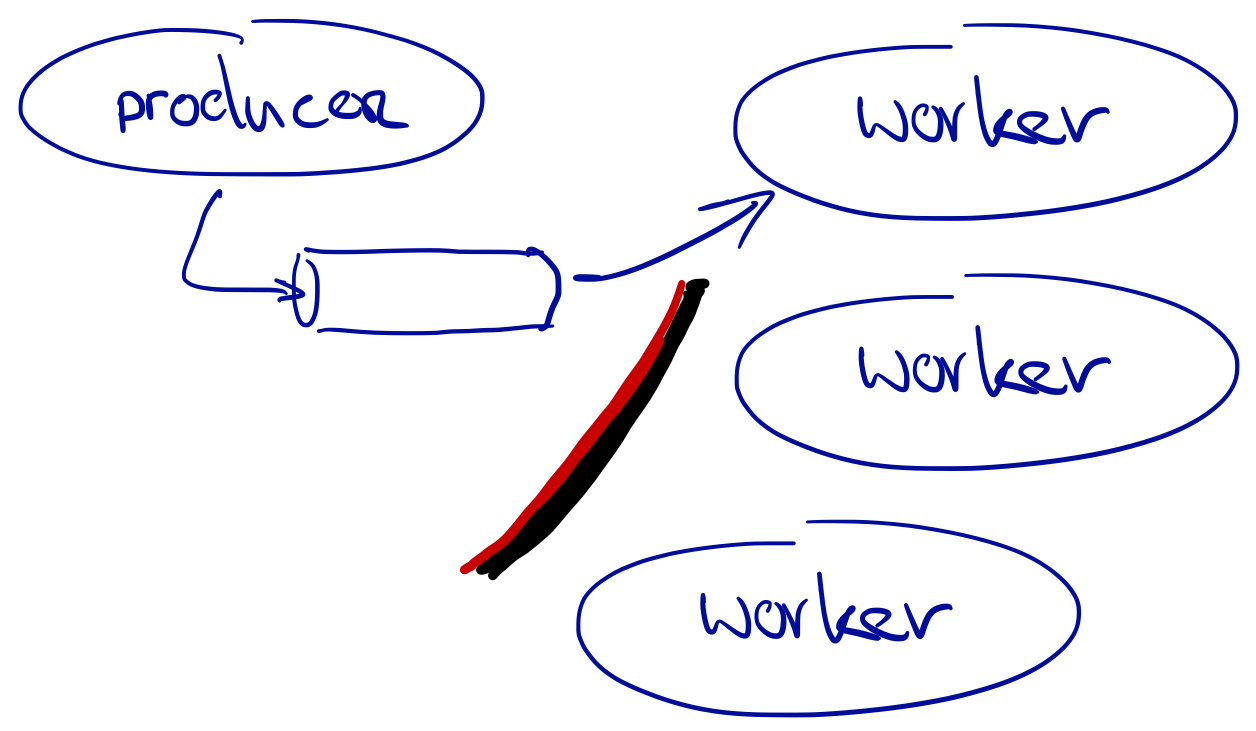
If we can partition the data and have each consumer process its own part of the data, the resulting throughput will be higher. We do need to find a good way to partition the data evenly; otherwise some consumers will be very busy, limiting how much we can scale the consumers for better throughput.
Automated end-to-end testing is another area where we have to deal with Connascence by Timing, in particular with browser-based tests. It takes time for the system under test to process changes and make these visible. Frontend applications add extra asynchronous behaviour. Probes are helpful and they are used by end-to-end testing frameworks like Playwright to handle timing and asynchronous behaviour.
We often have to deal with asynchronous, concurrent processes and the resulting Connascence by Timing. Sometimes we could remove it by replacing it with a synchronous call, but usually the async coupling is there for a good reason, like better throughput, scalability, independent deployability, or external services that are out of our control.
Eventual consistency
A trade-off we can make is being less strict in agreeing on timing, and settle for data to be eventually consistent instead of immediately consistent. Eventual consistency provides more options for the different parts of the system to eventually settle on a change. What ‘eventually’ means depends on the context and the domain, it could be milliseconds, seconds, the next day.
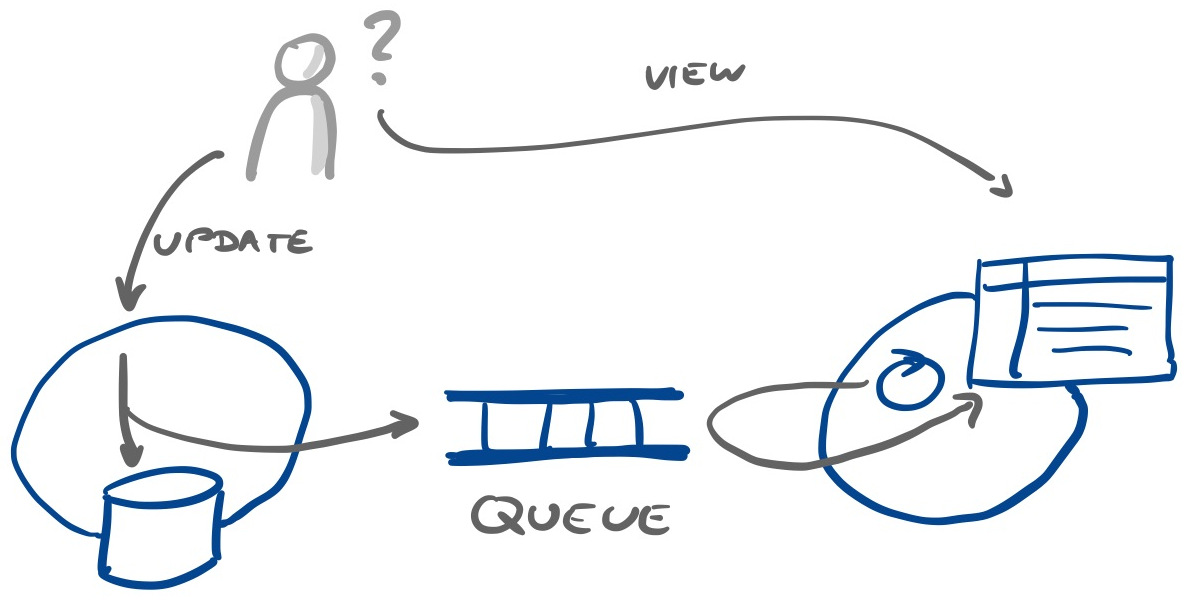
Again, there are trade-offs here. For example, eventual consistency makes it more complicated to detect that something did not happen: if the visible state has not been updated for X seconds, is it still waiting for the change to propagate or did it fail? Explicit queries at some time are needed for instance, whereas a timeout, optionally with a back-off algorithm is relatively simple.
Eventual consistency is a business decision
Showing an inconsistent state for a short amount of time is often good enough. Users are able to handle this and it is not worth adding the extra complexity of stricter consistency constraints. If I transfer money with my banking app, I often see the old balance for a second in the app until the transfer is processed, which is good enough.
What’s next
This post is part of a series on connascence and coupling. In the next post, we will focus on Connascence by Value, where two elements need to agree on a specific value.
- Part 1 - Introduction
- Part 2 - Connascence by Name and Type
- Part 3 - Connascence by Meaning
- Part 4 - Connascence by Position
- Part 5 - Connascence by Algorithm
- Part 6 - Connascence by Execution Order
- Part 7 - Connascence by Timing
- Part 8 - Connascence by Value
- Part 9 - Connascence by Identity
- Part 10 - Heuristics for managing coupling
Credits: watch thumbnail photo by Agê Barros on Unsplash