In our previous post on Hexagonal Architecture in a back-end, we mentioned wrapping ID generation and timestamps in concepts of their own. This might feel a bit over-designed, but we have reasons to do so. In this post, we share the trade-offs and rationale behind wrapping the standard stuff in abstractions of your own.
- Context
- It hurts when writing unit tests
- Standard stuff is stable…until it changes
- Standard stuff does the job…but does it communicate?
- Standard stuff offers all you need…and so much more
- Resolution: thinking from the domain
- Example: timestamps
- Example: unique identifiers
- Consequences
- Considerations
- References
Context
When we find ourselves using primitive types like integers, strings, and lists to represent something, we call this Primitive Obsession and we start looking for the hidden abstractions behind these primitive types. Our code makes assumptions about what the integer or string means, and those assumptions are spread out over the code, making it hard to change.
If we represent monetary amounts by integers for instance, we need to know how it works in every location where those integers are used. Is it cents, euros, dollars?
We tend to take a similar approach with other standard language or standard library things, like dates, timestamps, logging, UUIDs. Most developers just use these things in their code. They are standard, stable, why would you put extra boilerplate around those?
We have run into a number of issues that make us encapsulate the standard, stable things as well, rather than include them everywhere in our code.
It hurts when writing unit tests
If an object under test generates a timestamp, we cannot do an assert on the whole object, because the timestamps will differ. We can assert the individual attributes except the timestamp, but this makes our test long and unreadable. We can assert the approximate timestamp, but this makes the test even more obscure.
1
2
3
4
5
6
7
8
class Token:
def __init__(self, token):
self._token = token
self._created_time = datetime.now()
def test_initial_token_is_valid():
token = Token('1234')
assert token == ??? # how to test this?
It hurts even more when the code under test generates a UUID as a unique identifier. We have to work around that in our test.
1
2
3
4
5
6
7
8
class DiagnosticSessionCreator:
def create_with_id(self, team):
return DiagnosticSession(id=uuid.uuid4(), team=team)
def test_creates_valid_diagnostic_session():
creator = DiagnosticSessionCreator()
session = creator.create_with_id(team='Team A')
assert token == ??? # how to test this?
When testing code that creates a timestamp or an UUID, we could create a seam in the production code so that we have control over timestamp/UUID creation. In our test, we’d like to influence the line of code where the timestamp or UUID is created, to make it more deterministic.
Seam is a concept from Working Effectively with Legacy Code book by Michael Feathers, the classic book on handling legacy code and getting your first test in. A seam is a place in the code where you would like to vary behaviour, without having to change that code. You want to be able to vary the behaviour from the test.
The refactoring techniques from the Working Effectively with Legacy Code book, like extracting a creation method, are good techniques when dealing with legacy code (i.e. code without tests), but they do not necessarily make the code better - sometimes it gets worse before it gets better is the legacy code adage.
Standard stuff is stable…until it changes
The standard language and library constructs tend to be pretty stable, but still their APIs sometimes changes. Alternatively, you grow dissatisfied with your current logging library and decide this new library does the job better, faster, etc.
Having dependencies on the standard library all over the place will turn this into a migration nightmare. The standard stuff doesn’t change that much, but if it does it hurts.
Standard stuff does the job…but does it communicate?
The standard library names might be close to what we are trying to express in our domain, but usually there is a gap.
An example: imagine we have some sort of token that is valid for 60 minutes and we need to check if it is expired. We compare its timestamp plus 60 minutes to the current time:
1
2
3
4
5
6
7
8
9
10
11
12
from datetime import datetime, timedelta
class Token:
EXPIRY_IN_MINUTES=60
def __init__(self, token):
self._token = token
self._created_time = datetime.now()
# how to test this function?
def is_expired(self):
return self._created_time + timedelta(minutes=Token.EXPIRY_IN_MINUTES) < datetime.now()
We do not find the code in is_expired obvious at first glance. We tend to make
mistakes with the greater than/less then operators, fortunately our unit
tests will save us. This piece of code does not express clearly the intent of
timestamps in our code.
Standard stuff offers all you need…and so much more
Python datetime objects offer all kinds of methods, like isoweekday,
replace, - and we don’t need all of those for representing timestamps. For
tokens that expire, we only need to compare, add a time delta and maybe convert
them to and from strings (serialization).
Using an interface that is way broader than what the concept it is representing needs, creates an affordance for using the other stuff when it seems convenient, without having to think hard about the intent.
Resolution: thinking from the domain
As a response to the issues mentioned above, we prefer to approach this from a domain oriented perspective, especially when we are test driving the code.
From our domain, we see the need for a timestamp or a unique identifier. The
datetime object or the UUID value are mere implementation details. Our
domain cares about uniqueness of identifiers, not about UUIDs.
So we introduce a small domain concept representing the ‘thing’ we are dealing with, like a unique identifier. Introducing a domain concept means:
- Thinking about an intention-revealing, domain-oriented name for the thing.
- Thinking about the interface of the thing: what services does our domain need from this thing?
We encapsulate the knowledge around a timestamp or identifier in a type or class of its own. We can express more meaning in the code in that way and make the code better maintainable. This domain focus helps us to get to the core of the ‘thing’, instead of being guided by the peculiarities of the libraries at hand.
Example: timestamps
To work more effectively with timestamps, we can introduce a Clock class with
a now function to return the current time. For testing, we create a
FixedClock with the same interface that always returns a stubbed timestamp.
1
2
3
4
5
6
7
8
9
10
class Clock:
def now(self):
return datetime.now(timezone.utc)
class FixedClock:
def __init__(self, the_time=datetime.now(timezone.utc)):
self._the_time = the_time
def now(self):
return self._the_time
In Java or C#, we’d create a Clock interface with SystemClock and FixedClock implementations.
As a next step, we can wrap the datetime object in a Timestamp class:
1
2
3
4
5
6
7
8
class Timestamp:
def __init__(self, timestamp):
self._timestamp = timestamp
...
class Clock:
def now(self):
return Timestamp(datetime.now(timezone.utc))
The Timestamp class expresses the responsibilities of a Timestamp in this specific domain, and no more. We cannot accidentally introduce a new timestamp responsibility.
There are more reasons to wrap date/time related behaviour in an abstraction of its own: it provides a place to handle time zone related logic. Even more so once you realize that UTC and time zones have some interesting properties.
Example: unique identifiers
We use UUIDs as unique identifiers for our objects. Testing creation logic
that assigns a new id is hard because the UUIDs are not predictable. So we
introduce an ID concept and an IDGenerator.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
@dataclass(frozen=True)
class ID:
_uuid: UUID
@staticmethod
def from_string(potential_uuid_value):
...
try:
return ID(UUID(potential_uuid_value))
except ValueError as e:
return InvalidID()
@staticmethod
def invalid():
return InvalidID()
...
def __str__(self):
return str(self._uuid)
class IDGenerator(object):
def generate_id(self):
return ID(uuid.uuid4())
The IDGenerator gets injected in the creation code, here is an example from
the Online Agile Fluency® Diagnostic application:
1
2
3
4
5
6
7
class DiagnosticSessionCreator:
def __init__(self, id_generator=IDGenerator(), ...):
self.id_generator=id_generator
...
def create_with_id(self, ...):
...
diagnostic_session=DiagnosticSession(id=self.id_generator.generate_id(), ...)
This allows us to introduce a FixedIDGeneratorGenerating subclass of
IDGenerator which always returns the same stubbed ID:
1
2
3
4
5
6
class TestCreateWithId:
def test_creates_a_diagnostic_session_with_a_generated_id(self):
id_generator = FixedIDGeneratorGenerating(aValidID('12'))
creator = DiagnosticSessionCreator(id_generator=id_generator, ...)
diagnostic_session = creator.create_with_id(...)
assert diagnostic_session.id == aValidID('12')
The aValidID function is a test data
builder for IDs. We have published the ID,
IDGenerator and corresponding test data builder code as part of the
quiltz-domain library on GitHub.
We introduced the IDGenerator early on in the project so that we’d be in control of id generation in our tests. Later on, we decided to introduce the ID concept to represent identifiers, but also invalid identifiers - incoming data in a web application could be invalid and we want to be able to work with invalid data conveniently. We found out the hard way that we had waited too long with introducing the ID class, because UUIDs were all over the place. It took us a few hours to refactor.
Narrator: “If you leave this for a few years, it may be hard to recover from, and will repeatedly lead to surprisingly interesting defects. For instance, when over time you use different frameworks that generate different shapes of UUIDs and handle them as strings everywhere.”
Consequences
If we wrap standard language and library primitives in meaningful abstractions of their own, we see the following benefits:
- Code reflects our intent better and gets less cluttered by language or standard library constructs.
- Code becomes better testable, as we have more behaviour under control.
- We explicitly document what we use from the standard library and we insulate ourselves from changes in these dependencies. This lowers the cost of testing and replacing them when necessary.
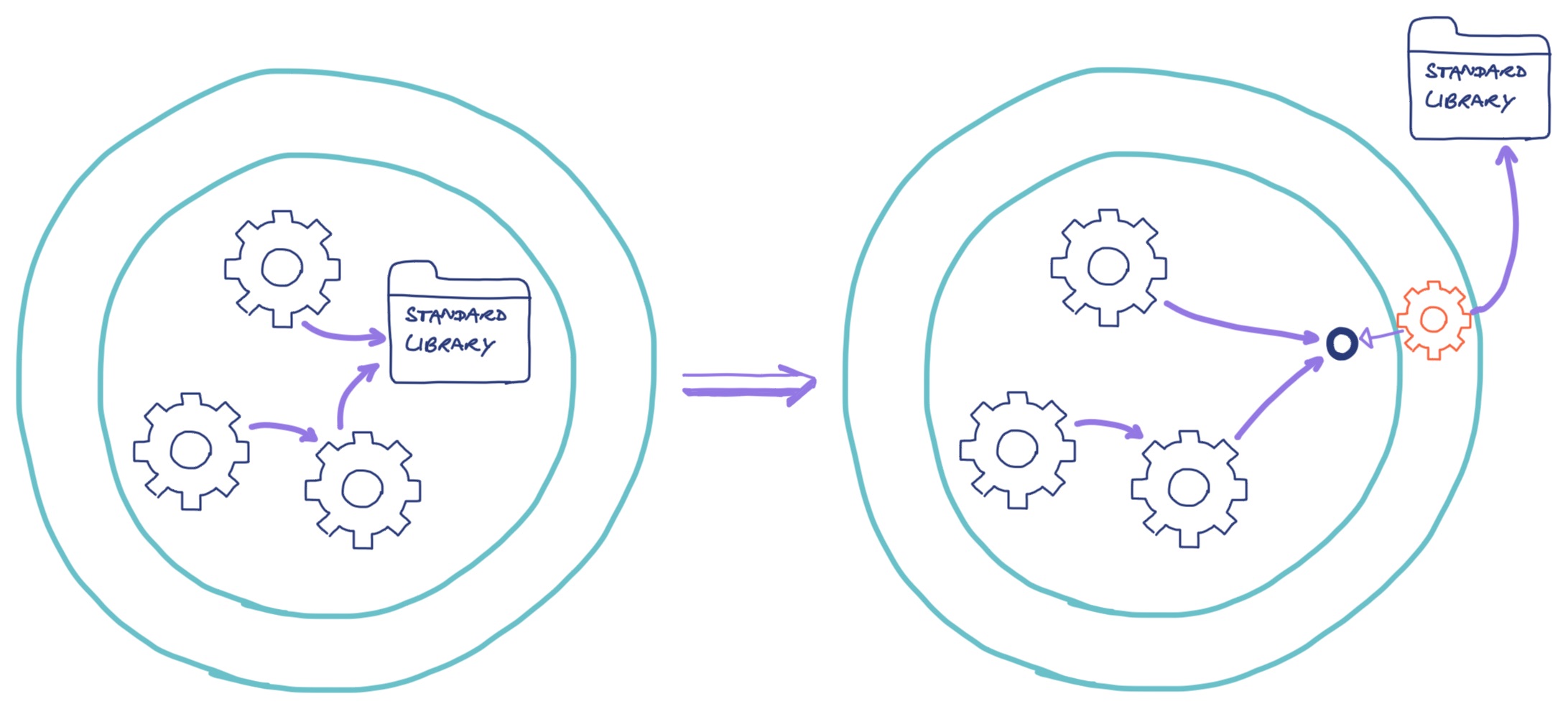
Seen through a Hexagonal Architecture
lens, we see standard library stuff as external dependencies that we want to
separate from our domain. The implementations of our Clock and IDGenerator
can be seen as adapters. This is in line with the Hexagonal Architecture
principle of domain in the centre, libraries & frameworks on the outside.
Considerations
Initially, it feels like overkill to wrap stable, well-known, relatively simple standard library constructs in abstractions of their own. It feels like extra work, not adding much value initially when the codebase is still small and innocent. The extra effort is limited however and will save you many hours later on.
So we sometimes start out with directly using the library within our domain code. We tolerate libraries, as they are not in control and are less intrusive than frameworks. We wrap them later on when we notice logic growing around the use of that library. The longer we wait however, the more painful it becomes.
With this approach, we are not testing the actual timestamp or UUID generation in our unit tests. That’s ok, we do not need to test standard library behaviour. We trust it to do its job correctly. Even if we wouldn’t trust it, we would write a few specific characterization tests to capture its behaviour. These can be useful to ‘fix’ the behaviour and get early feedback if a newer version subtly breaks the API.
Creating small, domain-oriented abstractions around standard library primitives creates a new home for responsibilities. This helps in the quest of What To Put Where.
References
- If you’d like to learn the vocabulary of code smells like Primitive Obsession and appropriate refactorings, have a look at our Code Smells & Refactoring cards
- The concept of Connascence, a model for reasoning about coupling in code, provides a foundation for wrapping standard library things in your own abstractions
- Read more about the Hexagonal Architecture pattern in our series of posts on this topic
- Working Effectively with Legacy Code (2004) by Michael Feathers is the standard work on refactoring legacy code. Even after 17 years, it is still relevant for the problems we run into today.
Credits: thanks to Willem for editing and helping improve this post.