When we visit clients and discuss the architecture of their software systems, we often notice that people conflate different concerns under the term ‘architecture’. They tend to mix logical concerns with deployment concerns. Examples of logical concerns would be domain logic, domain dynamics, and how these are connected. Deployment concerns can be for instance REST APIs, components, microservices, and lambdas. The recent ‘cloud native’ movement has made this even worse, especially with serverless infrastructure concepts.
In this post we will show how separating logical and deployment views on the architecture of your software systems facilitates more fruitful conversations. We will start with some of our experience on what happens when you don’t.
Table of contents
- Views on software systems
- An example
- Taking a fresh view
- This is not a new idea
- But we are cloud native!
- Microservices will solve this!
- But it is all connected!
- Conclusion
- References
Views on software systems
An example of mixed architecture concerns is the post on What a typical 100% Serverless Architecture looks like in AWS by Xavier Lefèvre. The post gives a nice view into some of the infrastructure decisions they have made. The diagram in the post however primarily talks AWS Lambdas, S3 buckets, API gateway, etc. It is not about the domain concepts and how they relate (they talk a bit about it in the text). Neither does it focus on how business logic is mapped onto the infrastructure concepts. The view presented is a deployment view, not a logical view of the system.
I am not saying this view on a system is wrong. On the contrary, I find the 100% serverless post insightful in how they are using the serverless infrastructure concepts and how all the services in the infrastructure are connected. It is however one of many views on a software system. For any non trivial software system, we need multiple views, to keep complexity manageable.
Multiple views enable us to make trade-offs about:
- business rules,
- how concepts work together,
- how everything is mapped onto infrastructure.
Mapping onto is key here - we start from what we want, and map that on the infrastructure we can get. Sometimes we let cool infrastructure inspire us, but we always go back to our wants and our users’ needs.
An example
Let’s look at an example, loosely based on a project we worked on some time ago. The system is a web shop. One of the back end components processes product orders. This component creates/stores/retrieves orders from a relational database; it also offers an order overview with full text search functionality, and the possibility to export of orders per time period. For the search and export, an Elastic Search based index was used.
All three functionalities were closely related, being about the same Order Aggregate. Seen through the Hexagonal Architecture lens, it looks like this:
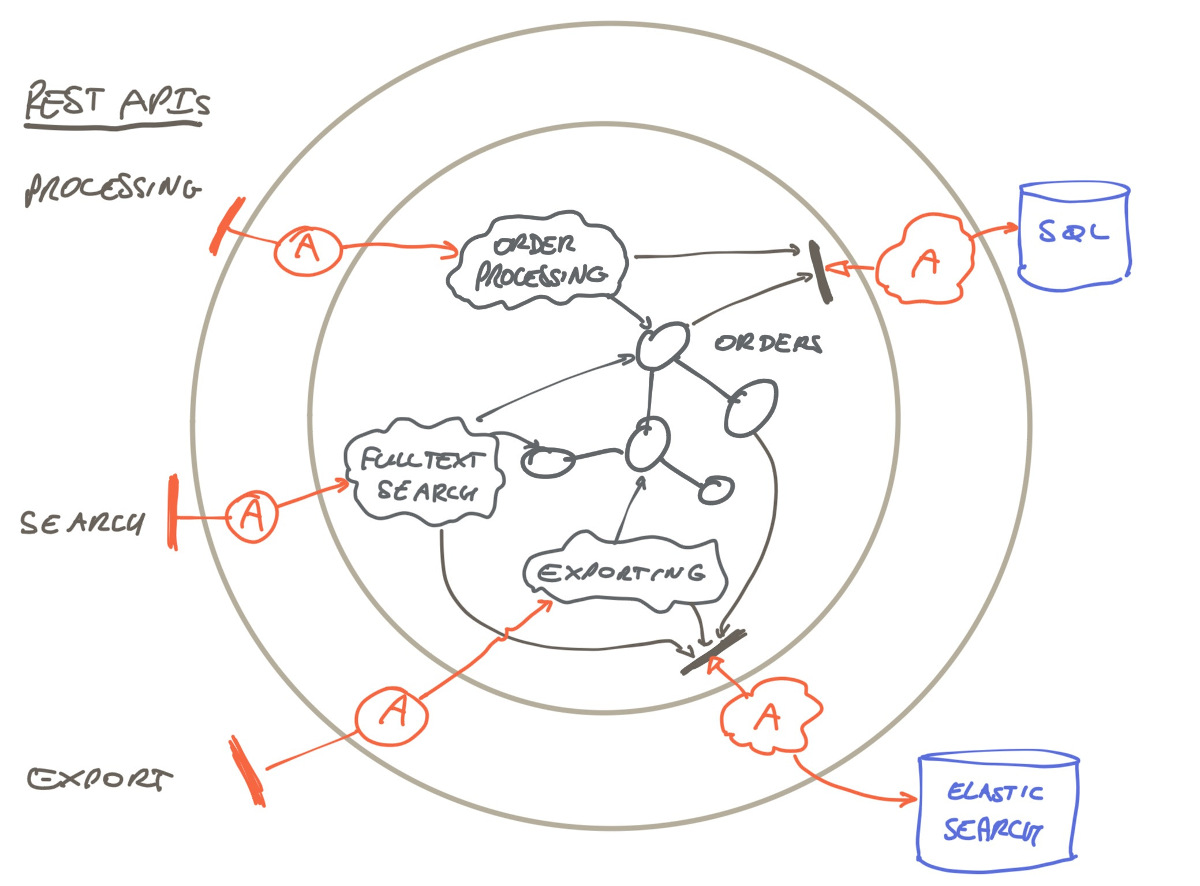
The red ‘A’s are the primary and secondary adapter, REST controllers, SQL database adapters, and Elastic Search adapters in this case.
An architecture principle we followed was that each component is responsible for its own data storage, which amounts to no shared logical databases between components and no inter-component coupling via a database.
Initially this component was deployed as a single unit: one Docker image, a few instances running on AWS EC2 machines to handle the load. Then we started noticing some issues with the component. The distinct functionalities turned out to have quite different runtime characteristics:
- Exports are run only a few times a month, but when running they have a very high CPU and memory demand; this sometimes caused the unit to be unavailable, impeding the primary business process of order processing.
- Sometimes complex search queries triggered heavy processing, reducing responsiveness of the unit, again affecting the primary process.
The unit was split it into 3 components: order processing, search and export, and they were put in separate git repositories. We introduced shared libraries to handle the dependencies between the code bases.
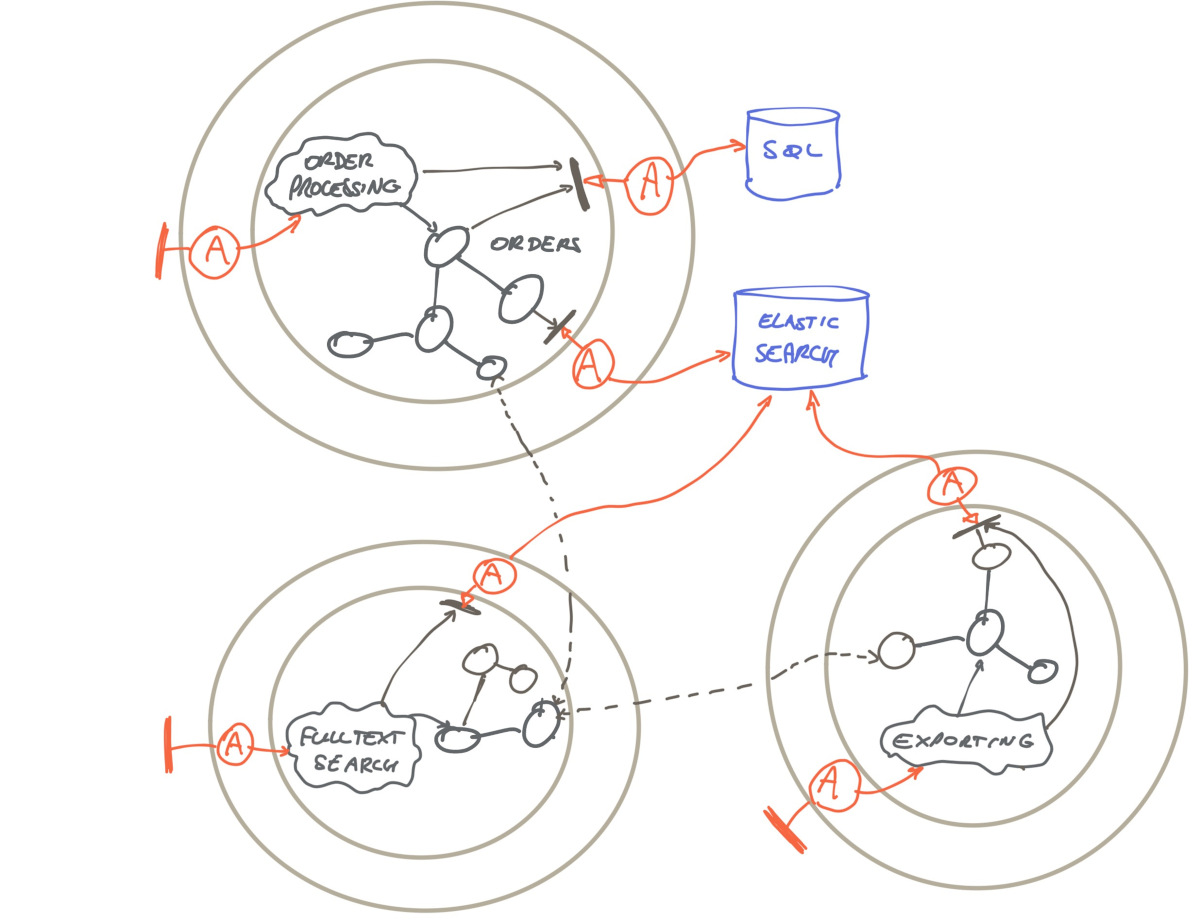
The 3 components got their own deployment parameters: the export component can be a single instance with a lot of memory, the order processing component can be configured for auto scaling during busy times, etc.
But now we have 3 components that are tightly coupled. They have some “interesting” dependencies across the components, as indicated by the dotted lines. The components also share databases, so they violate our architecture principles…or not? Did we create a mess or…?
We have one view combining dependencies, logical coupling, and runtime issues. Because these different concerns get all mixed up, things get unnecessarily complicated.
We split the codebase, but pulling things apart is not necessarily decoupling! As a matter of fact, the coupling is still there, but obfuscated.
We have actually made things worse…
Taking a fresh view
What happened? We split the component and its codebase into three because of runtime concerns. Let’s take a different perspective on this: logically we can continue to see it as a single coherent component with one codebase, one git repository. There is some coupling here, but it is local to this codebase and manageable. So we are back at the initial architecture picture:
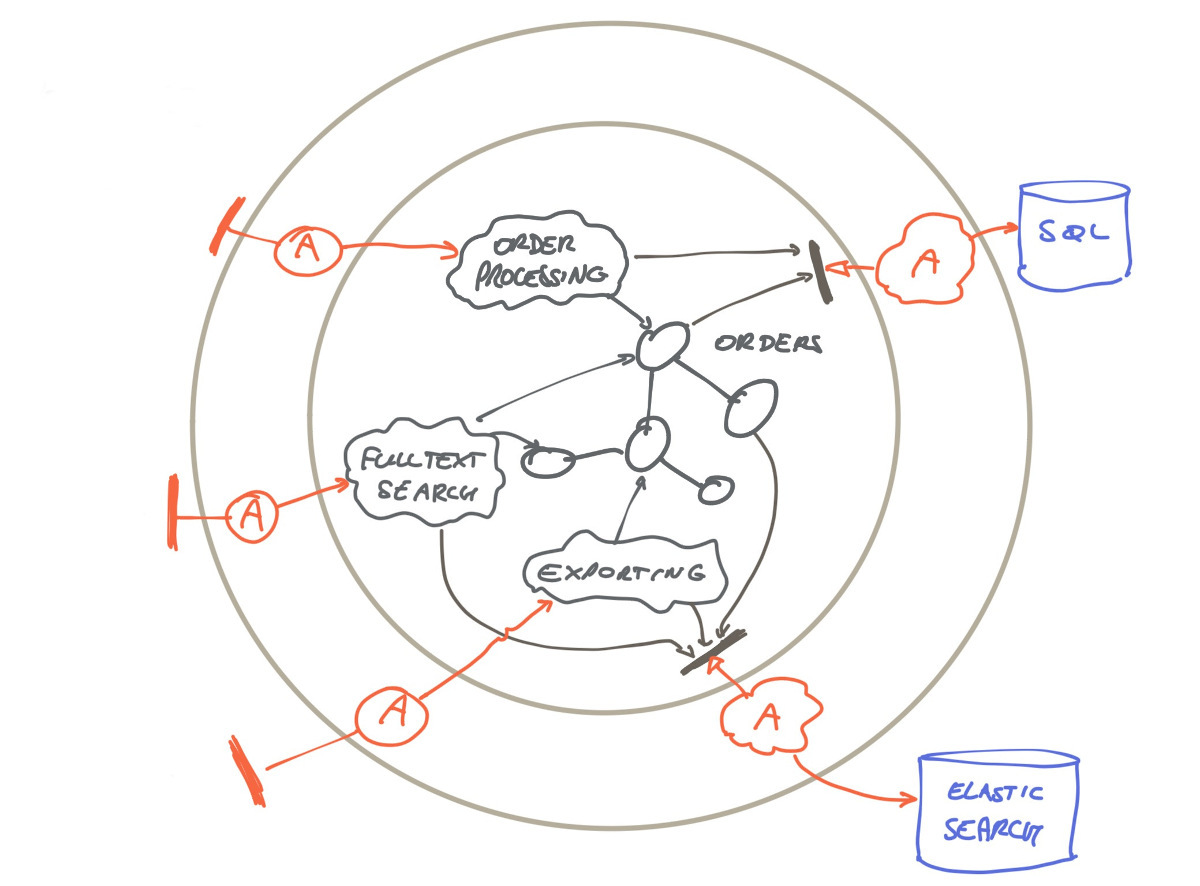
This is the logical view on our order processing subsystem. It is about our domain logic and how it connects to its outside world.
We can create three deployables from this single logical component, to accommodate for the different runtime characteristics. This allows a better balance between different architectural concerns, like coupling/cohesion, runtime performance, scaling.
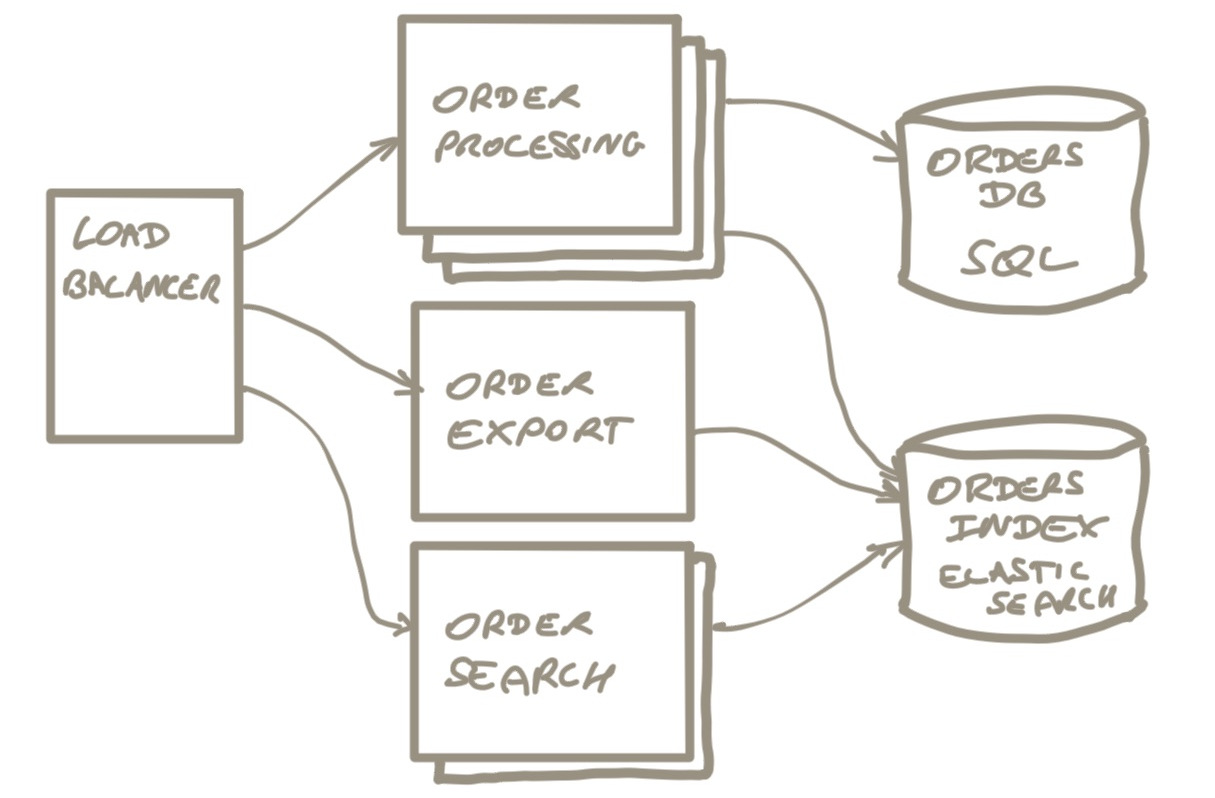
This is the deployment view of our order processing subsystem. It is about what units of deployment we have, how they depend on each other and on database services.
So by separating the two views, we can discuss logical concerns and deployment or runtime concerns separately. This allows us to make better trade-offs. Having one logical component split into three deployables does incur a cost for example: we need to take care of potential compatibility issues during deployment, when during a short period of time multiple versions of the component are active. The benefit of allowing different runtime characteristics outweighs these costs.
This is not a new idea
We did not invent this idea of having different views on your system’s architecture. It has been around for quite some time and we would like to mention a few of our sources of inspiration.
4+1 Architecture View Model
Philippe Kruchten’s 4+1 Architecture View Model (PDF) dates from 1995. This model distinguishes the Logical View, the Process View, the Development View, the Physical View, and the Scenario (or Use Case) view.
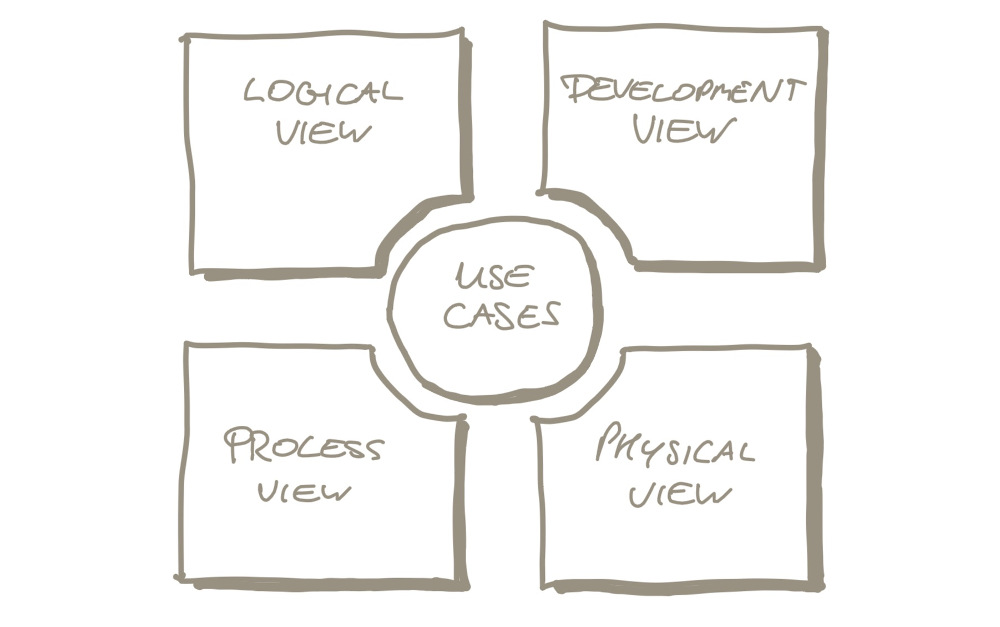
- Logical view: supports functional requirements and would contain domain objects
- Process view: addresses things like concurrency, system integrity, fault tolerance
- Development view: focuses on the organization of software in modules, libraries, subsystems; the concept of Bounded Contexts from Domain Driven Design could fit here
- Physical view: takes into account system qualities like availability, performance, scalability; it visualizes how the software runs on a network of nodes
- Use case view: small set of important scenarios that show how all these views work together
Visual Architecting Process
In 2019, I attended the Software Architecture workshop from Dana Bredemeyer and learned about the Visual Architecting Process by Ruth Malan & Dana Bredemeyer. They have a lot of great material about architecture and I highly recommend this course.
One of the concepts I learned related to this post is four levels of architecture: Meta Architecture, Conceptual Architecture, Logical Architecture and Execution Architecture.
- Conceptual: about components, collaborations and their rationale
- Logical: fully defined interfaces, rich description of responsibilities
- Execution: mapping components on physical resources, validate runtime quality requirements
- Meta: higher level guiding ideas, vision, philosophy & principles
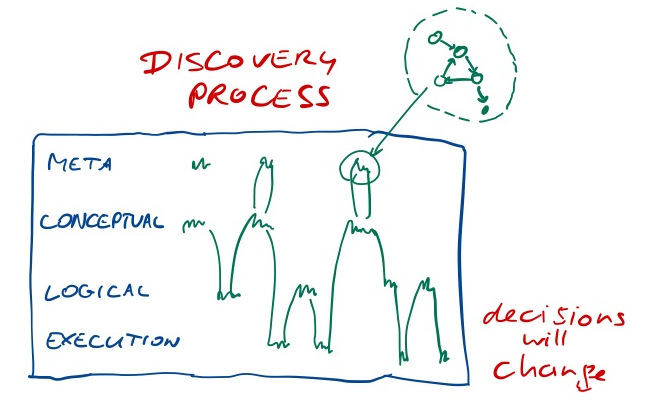
The process is not linear but highly iterative: we take design decision at for instance the conceptual level, validate & record it, get interesting feedback from elaborating it on the Logical level, so we revisit the Conceptual level. Along the way, we discover architecture principles and guidelines that we consider at the meta level (the picture is from the notes I took at the course).
…and more
Simon Brown’s C4 Model for Visualising Architecture also supports multiple perspectives.
But we are cloud native!
We noticed the movement to a cloud based infrastructure tends to make the confusion worse. At various clients, we have seen developers enthusiastically embracing cloud services, making the infrastructure the leading view. We understand that developers need some focus on cloud services, because cloud offerings are quite extensive and complicated, and have a steep learning curve.
Conflating the different views or leaving the conceptual view implicit will make it even more complicated however. Serverless for instance does not mean you can stop thinking how to model your domain in software and how to manage dependencies. It does take away some infrastructure concerns, but you still need to decide how to map your domain and logical components onto the infrastructure.
An interesting development in this area is linking financial models to (serverless) infrastructure. With cloud based infrastructure, we are moving away from mostly fixed cost infrastructure to more and more variable costs and pay-per-use. The deployment view can provide interesting financial feedback on logical design decisions. Refactoring could have direct financial benefit. Simon Wardley (of Wardley Mapping fame) talks about this in the webinar he did together with Jamie Dobson on DevOps is the New Legacy. Or have a look at Why the fuss about serverless? and FinDev and Serverless Microeconomics: Part 1 if you’d like to learn more.
Microservices will solve this!
No.
Microservices, or rather appropriately sized services, are a deployment concept. They are about what things you deploy together and what things need to be deployed separately. The logical view of your software system is about capturing your domain and managing dependencies and consistency boundaries. If you conflate the logical design with microservices, it becomes hard to make good decisions.
Alberto Brandolini elaborates on this in his excellent post About Bounded Contexts and Microservices. He mentions the Bounded Context concept from Domain Driven Design, which is all about the logical architecture.
But it is all connected!
It is. But that does not reduce the value of having separate the views. We still have to map the logical view onto the deployment view, which might result in some restrictions on the logical design decisions we take. But with separate, clear views, this becomes easier. This is in a way analogous to well-factored code that is easier to optimize for performance than entangled code.
Conclusion
Having just one view on components mixes different concerns and makes it harder to decide about e.g. dependencies. This can lead to suboptimal design decisions, such as splitting code at the wrong spots or a suboptimal runtime environment, which ultimately lead to production issues.
Having a logical view and a deployment view allows you to address different design and runtime trade-offs separately. Different views enable you to have more focused, fruitful conversations about the architecture and design decisions you make for the systems you develop.
References
- Gregor Riegler, Levels of Modularity
- Vasco Figueira, Microservices - architecture nihilism in minimalism’s clothes
Credits: thanks to Willem for editing and helping improve this post.