Hexagonal Architecture, also known as Ports and Adapters, is getting quite a bit of (well-deserved!) attention recently, especially in the Domain Driven Design community. Hexagonal Architecture is not a new thing: it was originally thought up by Alistair Cockburn (of Agile Manifesto fame) in the 90ies.
Hexagonal Architecture or Ports & Adapters is an architectural pattern that guides you in structuring a component/service/application and managing dependencies. It is not a best practice! A pattern solves a problem in a context, and therefore it comes with trade-offs. Hexagonal Architecture usually pays off in our experience. We have been applying and teaching it for 10+ years, and it has proved its worth.
There are quite a few good reads about Hexagonal Architecture. We’d like to add our view and some of our experience with it.
What did we use before hexagons?
We often used a layered architecture, with a small number of layers. Dependencies go downwards. The layers come by different names, for example:
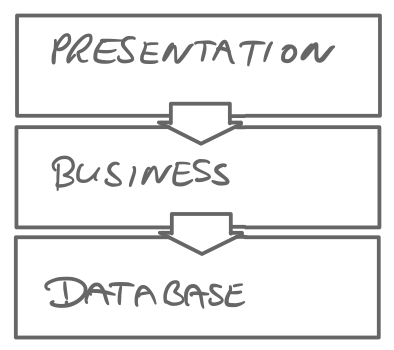
Layers are not the only way to structure systems, but a layered architecture seems to be the default. This has probably its origins in the ISO OSI model for networked systems, which has 7 layers from physical wires & waves up to the application.
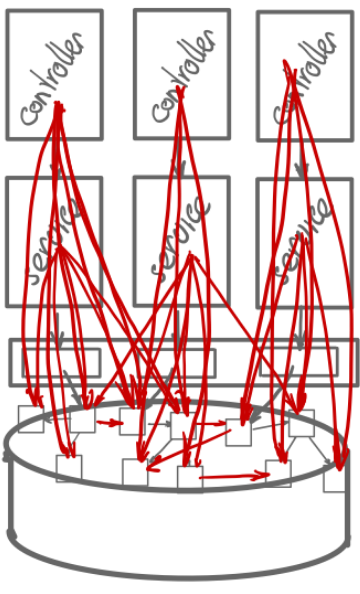
Layered systems can have several undesired consequences. Layered systems tend to suffer from gravity: everything depends directly or transitively on the bottom layer. This leads us to believe the bottom layer should be very sturdy to carry all the weight of the layers on top. In one project Rob was a member of the ‘Shared Code Base (SCB) Team’. The team (Rob included) felt very important. A tremendous amount of energy went in developing SCB features. Other teams had quite some trouble integrating SCB releases. And the SCB contained features that where never used. In hindsight, SCB efforts weren’t very effective.
Layered systems tend to suffer from leaking abstractions as well. In our consulting practice, we see that in systems with a database or data layer on the bottom, everything tends to depend on the database entities, and the code base is a horror to work on.
The Hexagon
Our software should be about the business we’re in, about the problem domain we are working in. It should speak domain language, not technicalities. Hexagonal Architecture puts the domain logic front and centre. We create models of our domain, agree on a ubiquitous language and ensure the domain concepts end up explicitly in code. This results in executable models of our domain that facilitate ongoing exploration and conversations with our stakeholders.
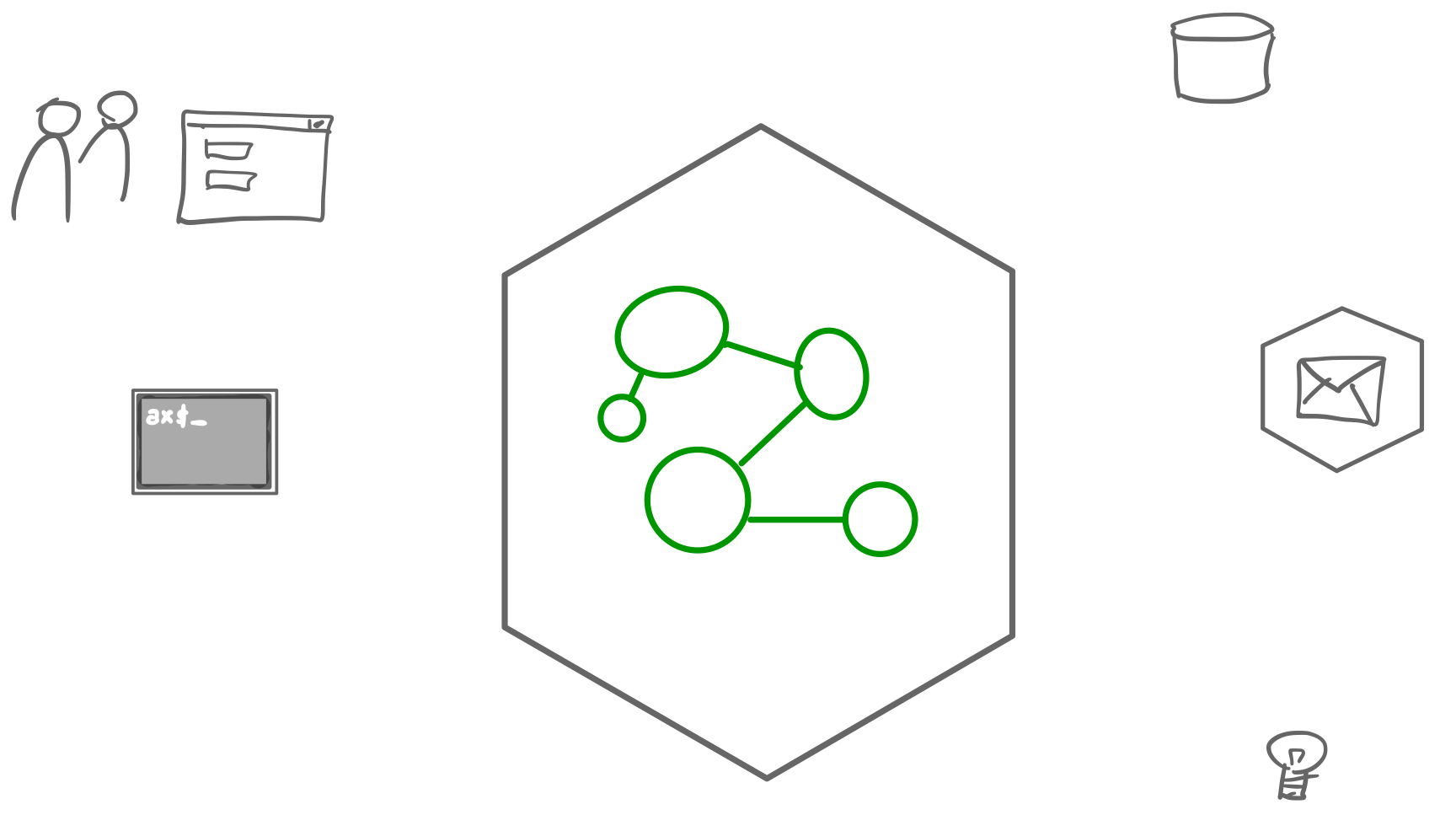
We still need the technical stuff though. We need to use databases, messaging services, device drivers for lights or motors. We provide graphical user interfaces, external APIs, command line interfaces. So our hexagon with central domain needs to interact with the outside world. It does this via Ports.
A Port is a set of interactions with the outside world that share the same intent. We distinguish Primary Ports and Secondary ports:
- Primary ports drive our system, for instance a web interface or an API,
- Secondary Ports are driven by our system, for instance a database or messaging service.
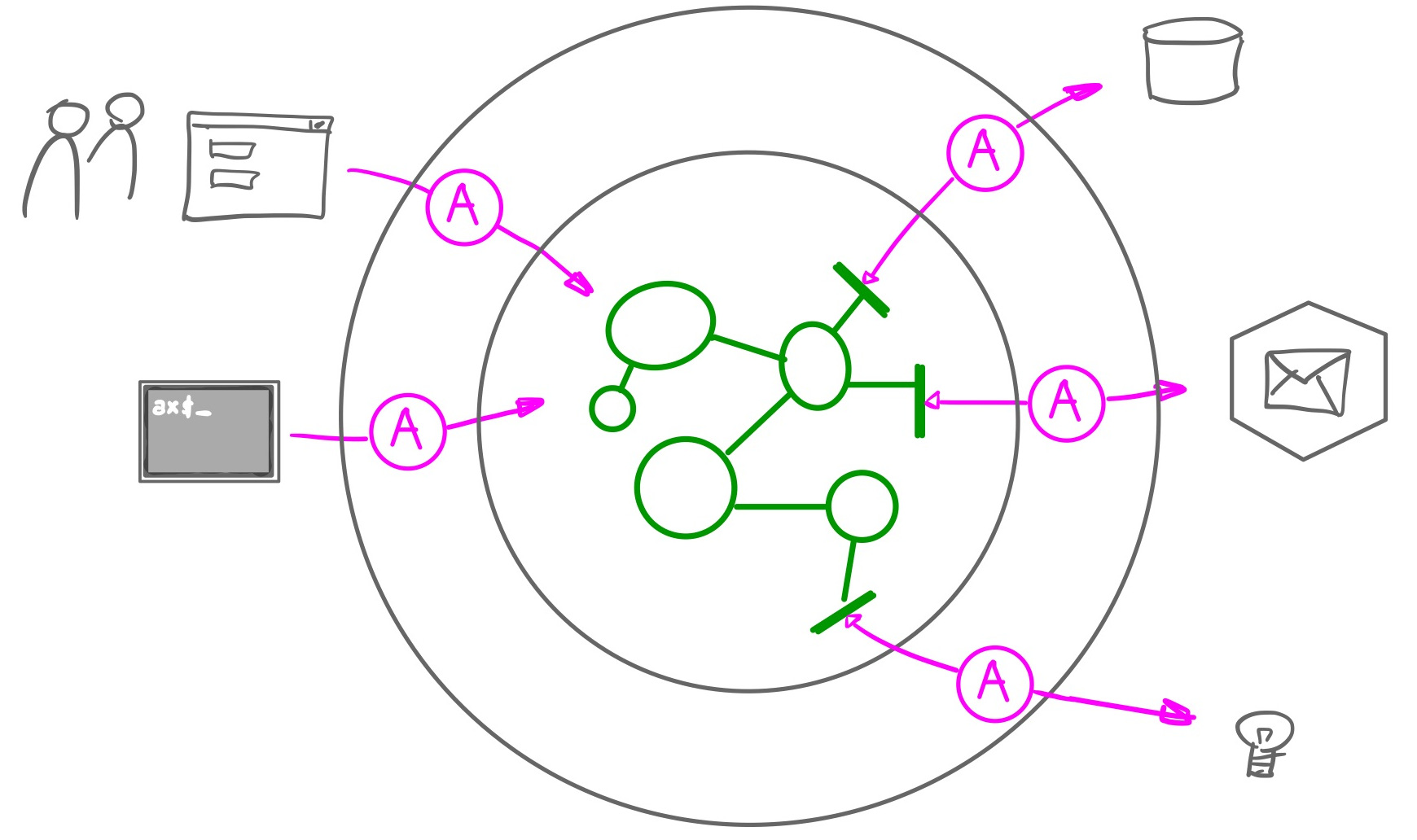
To connect the domain logic with the outside world, we create Adapters that map the outside world onto the inside world and the other way around. The guiding principle here is: dependencies go outside-in: our domain does not depend on specific adapters and technicalities, the adapters depend on the domain logic. This is dependency inversion applied to software architecture.
Adapters
For Primary Ports, it is not hard to see that dependencies go from the adapter to the domain. We can introduce an interface or Facade in between, so that our primary adapters are only exposed to the specific domain logic they need and nothing else (applying the interface segregation principle - manage dependencies via small, specific interfaces).
How does this work for Secondary Ports, where our domain is in control?
There will be a domain concept representing the service or device, often in the form of an interface. An example: in an order processing component, we store orders in a relational database. In the domain, we have an OrderRepository that can store a new order, retrieve all orders, and retrieve a specific order by its id. So the domain does not know about databases, queries, tables. It only knows an abstraction of a repository (the Repository Pattern).
The adapter will implement the interface. In our order processing application, it is a single class that contains the SQL queries and knows the specific database schema used. It can even be responsible for schema migration and evolution.
At compile time dependencies go outside in, at runtime everything will come together. Why is this important? Our domain only knows the essentials of the Order Repository, it is not affected by details about how it is stored, how queries look like, etc. We can work on the domain logic independently from the adapter. We can also have different implementations for the port, as long as they satisfy the port’s contract.
Sometimes an adapter is just a single class, sometimes it is a complex subsystem with multiple classes and functions. If we would use the Java Persistence API (JPA) to access the database, the JPA entities would be part of our database adapter. We don’t want our domain model to be driven by the peculiarities of how our data is stored in a relational database: a model that is fit for executing our business rules is not necessarily fit for storing and retrieving data in a relational way. We will have multiple models, optimized for different purposes. Our domain logic does not know all this, and it does not care.
Frameworks and libraries should know their place
Another implication of thinking Hexagonally is that libraries and frameworks reside in the outer circle, as part of the adapters. Frameworks can be a real nuisance because by definition they want to be in control. So we do our best to isolate them within the adapters and keep our domain model clean of them. We sometimes tolerate libraries in the center: libraries are not in control so they are less intrusive. But we tend to even wrap lower level library concepts like logging, date/time, and UUIDs, because these still tend to get in the way: unit testing code using timestamps, logging or randomness is a hassle. Furthermore, we use only a small part of what those libraries have to offer, but still expose our code to the whole libary.
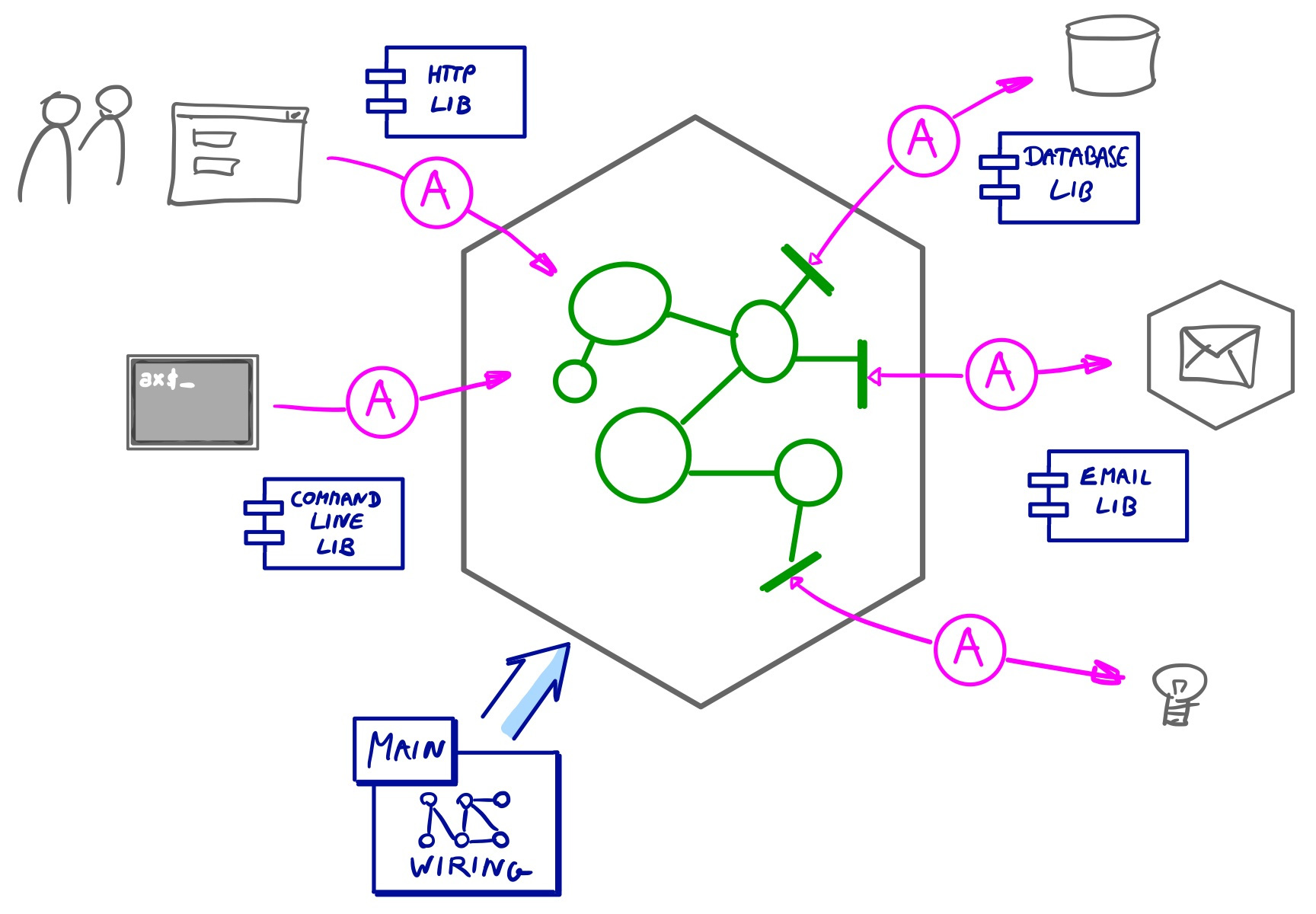
Although we often apply dependency injection, we tend to avoid dependency injection frameworks. We usually end up with a main class/function/file that instantiates all adapters and wires them together: very explicit, quite clear (and a bit boring).
Benefits
Hexagonal Architecture
- Allows us to focus on domain logic and is a good match with a Domain Driven Design approach
- Guides us in What To Put Where (WTPW) in the code. WTPW is crucial in making and keeping our code habitable. Getting something to work is half the effort, finding a good place is the other half.
- Allows faster, more focused automated tests for domain logic, as well as integration with databases and other external services.
- Guides structuring dependencies, resulting in a clutter-free domain model implementation.
- Allows independent and incremental evolution of concerns: we can let our APIs evolve at their own pace, the adapter mapping facilitates decoupling.
- Allows evolution of the domain model to suit business logic better, without having to break APIs or having to migrate a database on every small refactoring.
Trade offs
- Need to write adapter mappings. Sometimes it feels like you’re doing the same thing over and over again: database data objects, domain objects, API data objects are almost the same, why separate them? It feels faster to start without. In our experience, if you write the separate mappings and data objects from the start, you will soon find it facilitates separate evolution of domain logic, data models, and APIs. The different models turn out to be similar, but not the same.
- When adding a new feature, you will sometimes need to do work in several places: UI, API, domain, database. In an order processing component, all parts will have knowledge about an Order. If we add for instance the concept of discounts to an Order, this will affect UI, domain logic, database, and APIs. Hexagonal architecture does facilitate you in making these changes in a controlled way, keeping code continuously deliverable.
- Domain logic should not depend on adapter details, but sometimes properties of adapter technologies leak into the domain. You need for instance database transactions to keep the data in your relational database consistent. You’d like the corresponding port to be a clean and simple Repository, but you might need to add some concept of a transaction.
- Although it gives guidance, it also leaves a number of decisions open, for instance how to implement an adapter, whether to use data classes or just mapping functions.
- May require mock objects for testing the interaction with secondary ports.
Further reading & watching
- Highly recommended: Growing Object Oriented Software guided by Tests book by Steve Freeman & Nat Pryce. They use Ports & Adapters.
- The original article on Hexagonal Architecture by Alistair Cockburn
- Insightful presentation by Alistair Cockburn from 2017, on the history and the considerations that led to the Hexagonal Architecture: part 1, part 2, part 3
- Erwan Alliaume, Sébastien Roccaserra, Hexagonal Architecture: three principles and an implementation example
- Thomas Pierrain, Hexagonal architecture: don’t get lost on your right-side
- Tobias Goeschel, Hexagon, Schmexagon? – Part 1 - nice write up about Hexagonal Architecture linking it to Domain Driven Design
- More on the Repository pattern and more: David Garlan & Mary Shaw, An Introduction to Software Architecture (1994) (PDF)